


Author
Rabiya S A Bhaimia leads marketing initiatives for Smart City, Smart Health, and Industry 4.0 business unit at MulticoreWare. Her expertise lies in developing content, campaigns, and strategic marketing initiatives that translate complex AI and advanced technologies into compelling business narratives for global audiences.
Introduction: Bringing AI to the Smallest Edge Devices
Much of the edge AI conversation today focuses on GPUs, NPUs, and high-performance SoCs. Yet billions of low-power microcontrollers already deployed across industrial systems, healthcare devices, smart infrastructure, and consumer electronics present an equally important opportunity for AI at the edge. Advances in model optimization, quantization, DSP acceleration, and embedded AI runtimes are making it possible to run meaningful inference directly on these resource-constrained devices. As a result, MCU-based AI is expanding beyond traditional control functions into a growing range of intelligent edge applications.
At MulticoreWare, we help organizations optimize AI deployment across embedded platforms, from model design and runtime acceleration to hardware-aware implementation. In this blog, we explore how modern Cortex-M processors can support real-time AI workloads, using keyword spotting as a representative example of MCU inference in practice.
Why Cortex-M MCUs Matter for Edge AI
MCU-based inference enables AI in environments where power, cost, form factor, and connectivity are tightly constrained.
From industrial IoT and smart home systems to healthcare wearables and distributed sensing platforms, these devices demand:
- Ultra-low-power operation
- Deterministic real-time latency
- Minimal memory footprint
- Reliable on-device intelligence
By executing inference locally, MCU-based AI enables deterministic response times, improved privacy, reduced bandwidth requirements, and reliable operation even in environments with intermittent connectivity. Platforms such as the Arm Cortex-M85 significantly expand what is possible at the MCU edge. With Helium SIMD vector extensions, higher clock speeds, and improved memory capacity, Cortex-M processors are increasingly capable of supporting lightweight AI inference directly on-device.
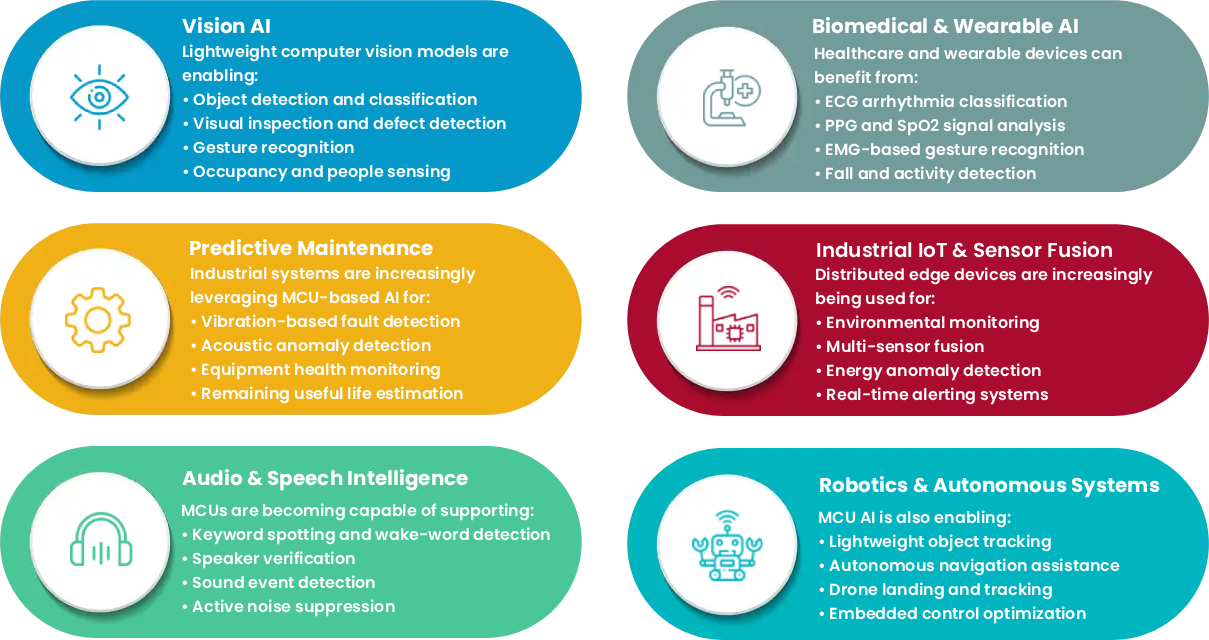
AI Use Cases Emerging on MCU Platforms
As MCU hardware and software ecosystems continue to evolve, a growing range of AI applications can now be deployed directly on microcontrollers.
Lightweight computer vision models are enabling:
- Object detection and classification
- Visual inspection and defect detection
- Gesture recognition
- Occupancy and people sensing
Industrial systems are increasingly leveraging MCU-based AI for:
- Vibration-based fault detection
- Acoustic anomaly detection
- Equipment health monitoring
- Remaining useful life estimation
MCUs are becoming capable of supporting:
- Keyword spotting and wake-word detection
- Speaker verification
- Sound event detection
- Active noise suppression
Healthcare and wearable devices can benefit from:
- ECG arrhythmia classification
- PPG and SpO₂ signal analysis
- EMG-based gesture recognition
- Fall and activity detection
Distributed edge devices are increasingly being used for:
- Environmental monitoring
- Multi-sensor fusion
- Energy anomaly detection
- Real-time alerting systems
MCU AI is also enabling:
- Lightweight object tracking
- Autonomous navigation assistance
- Drone landing and tracking
- Embedded control optimization

While these workloads span different industries and sensor modalities, they share a common challenge: delivering accurate AI inference within tight memory constraints, compute resources, power consumption, and cost.
To illustrate how these challenges can be addressed, we evaluated keyword spotting on an Arm Cortex-M85 platform, as keyword spotting combines continuous sensing, real-time responsiveness, and strict resource requirements, it serves as a useful example of modern MCU AI deployment.
Putting MCU AI into Practice: Keyword Spotting on Cortex-M85
Keyword spotting has become a common AI workload for voice-enabled devices because it requires continuous listening while operating within strict power and memory budgets.
Unlike many intermittent workloads, keyword spotting systems must remain responsive at all times, making them an excellent benchmark for evaluating MCU inference performance. To assess what is possible on modern Cortex-M platforms, MulticoreWare implemented and optimized a keyword spotting pipeline on the Arm Cortex-M85 using TensorFlow Lite Micro, CMSIS-NN, CMSIS-DSP, and Helium vector acceleration.
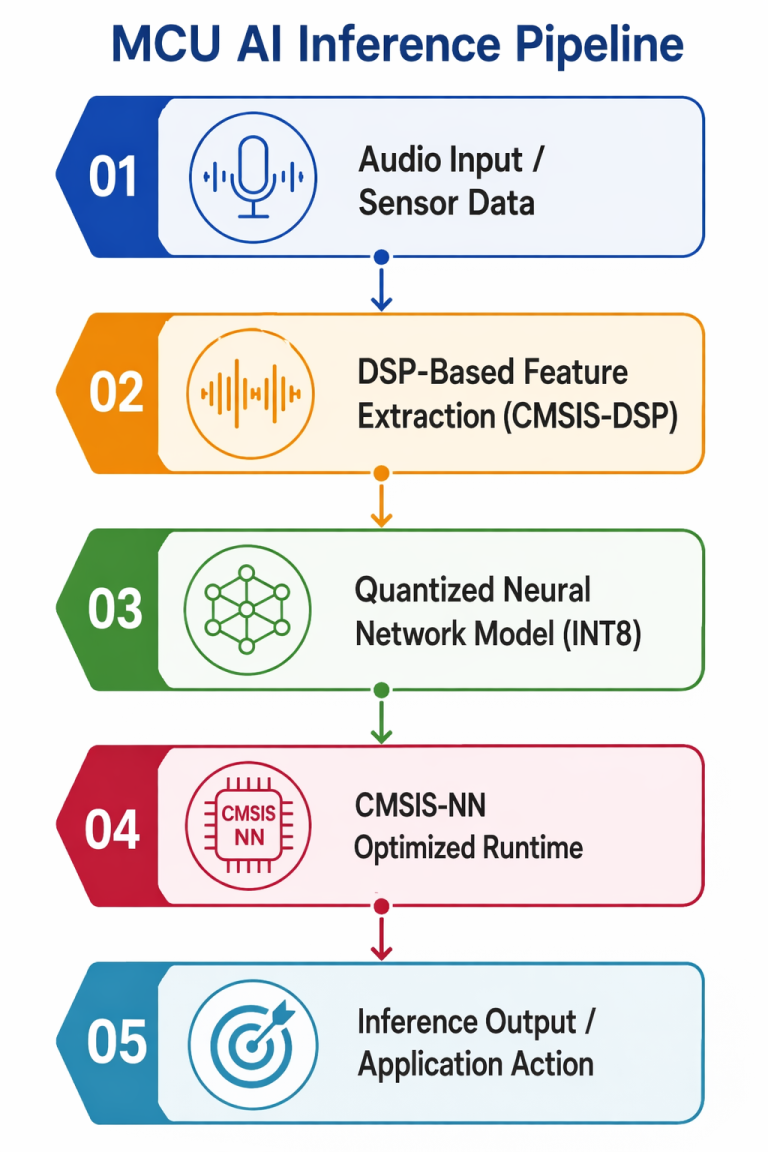
Engineering the End-to-End MCU AI Pipeline
Deploying AI successfully on MCUs requires more than simply compressing a model. The entire inference stack must be optimized around severe compute and memory constraints.
1. Model Optimization for MCU Deployment
Not all neural networks are suitable for MCU environments. Models must be intentionally designed for small Flash and SRAM footprints while still maintaining usable accuracy.
For keyword spotting workloads, MulticoreWare evaluated lightweight Tiny DS-CNN architectures optimized for low-memory deployment. INT8 quantization was applied to reduce model size and improve execution efficiency on integer-based MCU hardware while preserving inference accuracy.
2. Runtime and Kernel Optimization
Runtime efficiency is often the deciding factor between a functional prototype and a production-ready deployment.
Using TensorFlow Lite Micro alongside Helium-optimized CMSIS-NN kernels, convolution and fully connected operations were accelerated through vectorized execution. Additional optimizations including operator fusion, in-place execution, and memory-aware tensor management helped reduce runtime overhead and maintain stable inference within tight SRAM limits. On Cortex-M85 platforms running at 480 MHz, keyword spotting workloads achieved inference times in the ~40-60 ms range without external acceleration.
3. Real-Time Audio Preprocessing on MCU
Efficient preprocessing is equally important in MCU AI systems since feature extraction itself can become a latency bottleneck.
For audio inference, 16 kHz PCM audio streams were processed directly on-device using CMSIS-DSP FFT and Mel filterbank operations. By performing feature extraction locally, the pipeline maintained real-time responsiveness while minimizing preprocessing overhead and memory usage.
This enabled continuous audio analysis while preserving enough compute headroom for application logic and system-level tasks.
Performance Snapshot: Keyword Spotting on Cortex-M85
In our evaluation pipeline, Tiny DS-CNN keyword spotting models running with INT8 quantization and CMSIS-NN acceleration achieved:
- ~59.98 ms inference latency
- ~98 KB RAM footprint
- ~80 KB tensor arena usage
- Fully on-device execution
These results demonstrate that real-time audio AI is now practical even within highly constrained MCU environments.
MulticoreWare’s Approach to MCU Edge AI
MulticoreWare combines expertise across embedded systems, AI optimization, DSP, and hardware-aware deployment to enable production-ready MCU inference pipelines. Our work spans a wide range of MCU AI workloads across vision, audio, industrial sensing, biomedical signals, predictive maintenance, and edge automation applications, including:
- Model optimization and quantization for constrained devices
- DSP and signal-processing optimisation
- Memory-efficient execution strategies
- Sensor fusion and multimodal edge AI pipelines
- End-to-end deployment validation across latency, power, and reliability metrics
Rather than treating AI models independently, we focus on optimizing the complete edge inference pipeline from raw sensor input to final system response.
Conclusion: Enabling AI at the Extreme Edge
The future of edge AI will not be defined only by high-performance accelerators, but also by how intelligently AI can operate on the smallest and most power-constrained devices.
By optimizing models, runtimes, preprocessing, and deployment pipelines together, MulticoreWare enables real-time inference on Cortex-M class MCUs while maintaining low latency, minimal memory usage, and efficient power consumption.
The result is a new generation of embedded systems capable of delivering intelligent, always-on behavior at the edge, bringing practical AI to billions of devices where size, power, and efficiency matter most. To learn more about MulticoreWare’s MCU and edge AI optimization capabilities, write to us at info@multicorewareinc.com.


PERCEIVE: WHEN TELEMETRY BECOMES UNDERSTANDING
Networks generate enormous noise flapping interfaces, jitter spikes, microbursts, CPU swings, routing churn. Traditional tools collect this data but rarely interpret it. Agentic systems deploy perception agents that sit closer to devices switches, routers, gateways, radio units and continuously convert raw telemetry into meaningful context:
- A sudden CPU spike aligns with route reconvergence
- Bandwidth drops correlate with app behavior changes
- Jitter patterns suggest early congestion buildup
Telemetry stops being “data.” It becomes observation and intent on the foundation for real-time network awareness.

REASON: MOVING BEYOND ALERTS TO ACTUAL INSIGHT
Traditional NOCs respond to events. Agentic networks understand them. This reasoning layer blends forecasting models, anomaly classifiers, correlation engines, and LLM-based interpreters to answer deeper questions:
- What is actually happening?
- Why is it happening?
- What will happen if we do nothing?
Instead of “High latency detected,” you get: “East-west imbalance” indicates a forming congestion loop. Expected SLA breach in ~3 minutes”. That’s the shift from alerts to insight, from noise to clarity.

ACT: FROM INSIGHT TO AUTONOMOUS EXECUTION
In most networks today, the gap between “knowing the issue” and “fixing the issue” is massive. Engineers validate, triage, plan commands, schedule windows, and apply changes carefully. Agentic AI compresses this gap.
Action agents take the reasoning layer’s output and translate insight into safe, controlled operations. This isn’t blind automation. Its automation is guided by understanding. A congested link doesn’t trigger a rule; it triggers a decision because the system understands why it’s congested.

LEARN: NETWORKS THAT GET SMARTER EVERY DAY
Every action an agent takes is a feedback signal:
- Did latency improve?
- Did the jitter settle?
- Did throughput balance?
Reinforcement learning turns each intervention into a lesson. After months of operation, the system reacts faster, recognizes subtle patterns earlier, and adapts to conditions no human has ever manually tuned for. This is the real leap from automated tasks to autonomous improvement.

WHY THIS SHIFT IS INEVITABLE
Three pressures are forcing the industry toward autonomous, agent-driven operations:
- AI and east-west traffic are exploding, overwhelming traditional observability.
- Networks are hyper-distributed across cloud, edge, 5G, remote work, and microservices.
- Human-led NOCs can’t scale incidents to be more complex; expertise is scarce, and SLA expectations are unforgiving.
Autonomy is no longer a futuristic concept. It’s an operational necessity.
WHAT THIS MEANS FOR THE NOC
Agentic AI doesn’t replace engineers. It replaces the repetitive, reactive, real-time work that humans shouldn’t be doing. The NOC evolves from:
“Eyes on glass” → “Supervisors of autonomous workflows.”
That evolution is already underway across hyperscalers, telcos, ISPs, and large enterprises.
CLOSING THOUGHTS
The Perceive–Reason–Act–Learn loop is not hyped; it’s the new operating model for networks that need to learn, adapt, and self-correct at machine speed. Agentic AI enables networks to understand their own state, predict future behavior, take the right action at the right time, and continuously improve. Agentic AI isn’t just an upgrade; it’s a reinvention of how modern networks operate, marking the beginning of truly autonomous networking.
At MulticoreWare, we bring deep experience in AI-assisted operations, telemetry engineering, automation frameworks, and agent-driven architectures. If you’re ready to modernize your observability stack, reduce MTTR, or take your first step toward autonomous networking, we’re ready to partner with you. Build the next generation of AI-powered, future-ready network infrastructure with MulticoreWare. Contact us at info@multicorewareinc.com.


