


Customer
The customer is a technology company that develops a distributed GPU virtualization platform, allowing high-performance GPUs to be pooled, shared, and accessed remotely over standard network infrastructure. Their solution enables organizations to run compute intensive applications on centralized GPU resources while keeping the client environment lightweight and architecture agnostic.
Problem Statement
As adoption of ARM based edge devices and embedded systems continue to increase, the customer needed their platform to operate reliably across both x86 and ARM environments. The existing client implementation was originally built for x86 systems, with several components in the codebase relying on x86 specific assumptions around memory handling, driver behavior, and kernel execution flows.
This created inconsistencies when attempting to run workloads such as CUDA and PyTorch on ARM systems. Cross architecture test setups exposed issues in driver initialization, library compatibility, and runtime behavior, especially when the client and server were running on different CPU architectures.
Key challenges included:
- The client software did not natively support ARM based platforms
- CUDA and PyTorch workloads behaved inconsistently on mixed x86/ARM setups
- Several modules in the codebase implicitly assumed x86 semantics
- No established cross compilation or CI workflow for producing ARM compatible builds
To successfully support a heterogeneous deployment environment, the customer needed the platform to build, execute, and validate workloads uniformly across both architectures.
Solution Overview
MulticoreWare carried out a comprehensive enablement initiative to introduce full ARM architecture support into the platform. The effort began with a detailed audit of the build system and runtime code paths to identify architecture-dependent assumptions affecting compilation and execution.
The team refactored affected components to ensure consistent behavior on ARM, addressing issues related to CUDA driver handling, memory allocation patterns, and device side execution. In parallel, MulticoreWare implemented a cross compilation framework to generate ARM binaries reliably from an x86 environment, streamlining development workflows.
To ensure correctness, the team validated both PyTorch and CUDA workloads across all combinations of x86 and ARM client-server setups, confirming that kernel execution, driver initialization, and data path behavior matched expected baselines.
Core elements of the solution included:
- Adding full cross compilation support for ARM within the existing build system
- Refactoring code sections that assumed x86 behavior to operate correctly on ARM
- Resolving CUDA related driver and memory allocation issues observed during ARM tests
- Creating an x86 based Dockerized environment to enable reproducible ARM builds in CI
- Running extensive CUDA and PyTorch test suites to validate architecture consistency
These improvements ensured that both x86 and ARM clients exhibited comparable functional behavior and performance when accessing remote GPU resources.
Key capabilities of the solution includes:
Queue-based frame presentation
Implemented a decoupled frame presentation mechanism with caching to separate frame reception from rendering, reducing wait times and latency bottlenecks.
Workload-aware timeout optimization
Replaced infinite Vulkan waits with a formula-based timeout system in Mesa, improving synchronization efficiency and reducing rendering stalls.
Native Vulkan rendering enablement
Enabled missing Vulkan features required for Android Emulator Vulkan mode, bypassing Mesa translation layers and reducing frame processing latency.
Pipeline hotspot optimization
Leveraged profiling insights from Tracy, NVIDIA Nsight, and RenderDoc to identify and optimize critical rendering hotspots.
Remote rendering enhancement
Improved coordination between remote GPU rendering and client-side frame presentation to deliver smoother UI responsiveness across networked environments.
Technology Stack
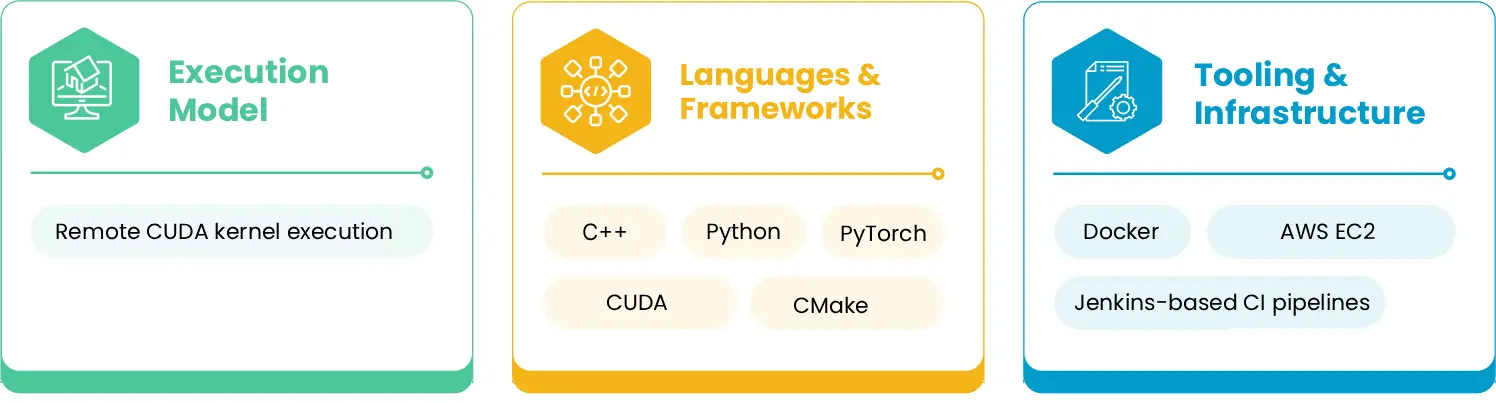
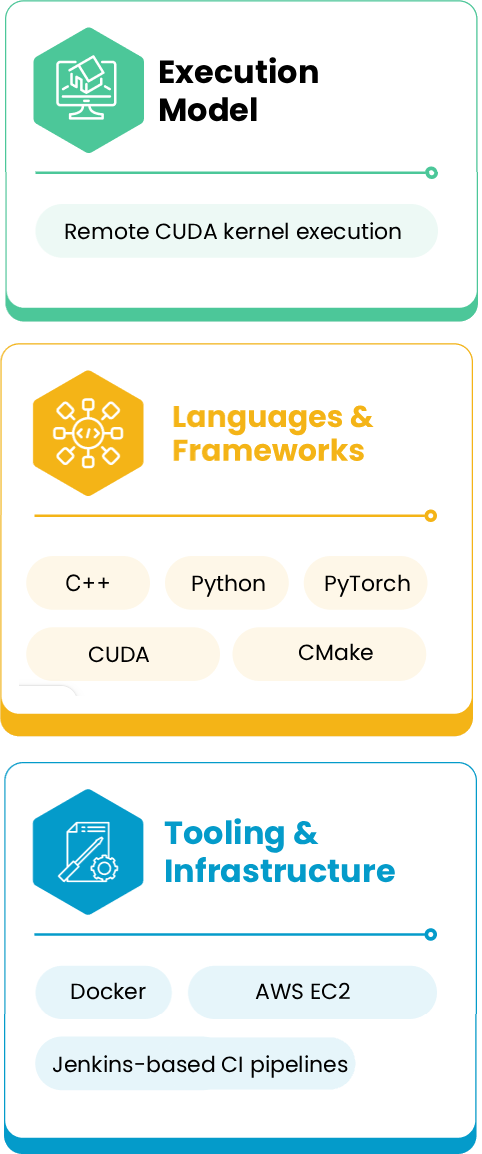
Business Impact
With ARM support fully enabled, the customer platform can now run on a much broader range of devices, including embedded and edge systems such as Jetson-class hardware. This significantly expands deployment opportunities in domains where ARM is the dominant architecture, particularly robotics, automotive edge computing, and distributed AI workloads.
The updated build and CI pipeline allows engineering teams to produce and validate multiarchitecture releases more efficiently, improving release cadence and reducing integration overhead.
Key outcomes include:
- Unified support for both x86 and ARM clients within the distributed GPU virtualization workflow
- Verified CUDA and PyTorch behavior across heterogeneous architectures
- Expanded applicability for edge to cloud deployments where ARM devices handle local data processing and use remote GPUs for heavy inference or training tasks
Conclusion
By introducing ARM compatibility into the client platform, MulticoreWare helped the customer bridge architectural gaps and extend their solution into emerging hardware ecosystems. The result is a more versatile, architecture agnostic system capable of supporting next generation distributed AI and compute workloads.
This project demonstrates how targeted compiler adjustments, cross architecture validation, and build system modernization can transform a single architecture platform into a scalable solution suitable for diverse deployment environments.
MulticoreWare partners with organizations to optimize graphics and application performance across remote and heterogeneous compute environments. Connect with our team at info@multicorewareinc.com to explore how we can support your roadmap.


